KafKa-在Spring中的使用
写在前面
Kafka的简单介绍可以看这个博客
Kafka的简单使用可参看之前的KafKa安装(翻译)
Spring for Kafka 的简单使用可参看这个博客
这里放一张我自己弄的简单的图

为什么使用消息队列
这里引用一下知乎答主的话:
个人认为消息队列的主要特点是异步处理,主要目的是减少请求响应时间和解耦。所以主要的使用场景就是将比较耗时而且不需要即时(同步)返回结果的操作作为消息放入消息队列。同时由于使用了消息队列,只要保证消息格式不变,消息的发送方和接收方并不需要彼此联系,也不需要受对方的影响,即解耦和。
- 校验用户名等信息,如果没问题会在数据库中添加一个用户记录
- 如果是用邮箱注册会给你发送一封注册成功的邮件,手机注册则会发送一条短信
- 分析用户的个人信息,以便将来向他推荐一些志同道合的人,或向那些人推荐他
- 发送给用户一个包含操作指南的系统通知
- 等等……
但是对于用户来说,注册功能实际只需要第一步,只要服务端将他的账户信息存到数据库中他便可以登录上去做他想做的事情了。至于其他的事情,非要在这一次请求中全部完成么?值得用户浪费时间等你处理这些对他来说无关紧要的事情么?所以实际当第一步做完后,服务端就可以把其他的操作放入对应的消息队列中然后马上返回用户结果,由消息队列异步的进行这些操作。
或者还有一种情况,同时有大量用户注册你的软件,再高并发情况下注册请求开始出现一些问题,例如邮件接口承受不住,或是分析信息时的大量计算使cpu满载,这将会出现虽然用户数据记录很快的添加到数据库中了,但是却卡在发邮件或分析信息时的情况,导致请求的响应时间大幅增长,甚至出现超时,这就有点不划算了。面对这种情况一般也是将这些操作放入消息队列(生产者消费者模型),消息队列慢慢的进行处理,同时可以很快的完成注册请求,不会影响用户使用其他功能。
简单概括就是:虽然这个用户操作在后端实际上有很多事要做,但是用户当下需要的只有部分事情的结果,那就可以把多出来的事情放入消息队列中慢慢实现。
当然消息队列也不局限于此,比如消息队列一般都内置了高效的通信机制,因此也可以用在纯的消息通讯,具体可以看这个博客。
//我是用消息队列来实现离线消息,消息到后端的时候,如果发现对应用户不在线,就把消息放入消息队列(生产者),等对应用户登录了(用户相当于一个消费者),会去获取订阅的消息,其实很扯淡……请不要效仿(离线消息搞个数据库不就行了嘛我就是吃饱了撑着用这个复杂地要死的来实现ಥ_ಥ),后来放弃了,觉得这个想法很傻逼(~ ̄△ ̄)~
况且kafka默认消息的保存时间是7天
Zookeeper
在KafKa安装(翻译)中,我们使用的是Kafka自带的zookeeper。
我们先来了解一下什么是zookeeper?
简介
Zookeeper是Hadoop分布式调度服务,用来构建分布式应用系统。构建一个分布式应用是一个很复杂的事情,主要的原因是我们需要合理有效的处理分布式集群中的部分失败的问题。例如,集群中的节点在相互通信时,A节点向B节点发送消息。A节点如果想知道消息是否发送成功,只能由B节点告诉A节点。那么如果B节点关机或者由于其他的原因脱离集群网络,问题就出现了。A节点不断的向B发送消息,并且无法获得B的响应。B也没有办法通知A节点已经离线或者关机。集群中其他的节点完全不知道B发生了什么情况,还在不断的向B发送消息。这时,你的整个集群就发生了部分失败的故障。
Zookeeper不能让部分失败的问题彻底消失,但是它提供了一些工具能够让你的分布式应用安全合理的处理部分失败的问题。
Kafka中的Zookeeper
ZooKeeper用于管理、协调Kafka broker。每个Kafka broker都通过ZooKeeper协调其它Kafka broker。当Kafka系统中新增了broker或者某个broker故障失效时,ZooKeeper服务将通知Producer和consumer。Producer和consumer据此开始与其它broker协调工作。Kafka整体系统架构如下图所示。

Zookeeper 主要用来跟踪Kafka 集群中的节点状态, 以及Kafka Topic, message 等等其他信息.。
没有Zookeeper 是不能运行起来Kafka 的。
Kafka将元数据信息保存在Zookeeper中,但是发送给Topic本身的数据是不会发到Zk上的。
新版本
早期版本的kafka用zk做meta信息存储,consumer的消费状态,group的管理以及 offset的值。
新版本中逐渐弱化了zookeeper的作用:
consumer使用了kafka内部的group coordination协议。
消费者offset不存放在zk,而是以Topic的形式(__consumer_offset)的形式存放在集群上。
结构

zookeeper里面,没有文件和文件夹的概念,只有一个叫做znode的节点概念。
znode既是数据的容器,也是其他节点的容器。(就是它里面可以放别的znode,也可以直接放数据)
Spring 配置
pom.xml
Spring整合kafka有两种方式:
spring-kafka
spring-integration-kafka
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>1.0.3.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework.integration</groupId>
<artifactId>spring-integration-kafka</artifactId>
<version>1.3.0.RELEASE</version>
</dependency>
差别大概就是
spring-integration-kafka封装更彻底,集成底层使用的就是spring-kafka。
spring-integration-kafka的配置里面还需要包括spring integration的部分(一种便捷的事件驱动消息框架)。
spring-kafka其实使用起来比spring-integration-kafka更简单一点
网上也有人说spring集成的Kafka的功能比Kafka API要少,建议直接使用Kafka API(当然我们这里不考虑这个意见( ˙³˙)( ˙³˙)( ˙³˙))
web.xml
<context-param>
<param-name>contextConfigLocation</param-name>
<param-value>classpath*:spring-kafka-*.xml</param-value>
</context-param>
这里注意一下
spring-integration-kafka
Outbound Channel Adapter 和 Message Driven Channel Adapter 分别是
spring-integration-kafka 中对应 kafka 的生产者和消费者的适配器。
Outbound Channel Adapter用来发送消息到Kafka。消息从Spring Integration Channel中发出,一旦配置好这个Channel,就可以利用这个Channel往Kafka发消息。(MessageChannel类)。
Message Driven Channel Adapter 则接收并转化 kafka 消费者接收到的消息为 Spring 消息。
因此,我们的创建、接受的消息内容都是 Spring 消息。
spring integration
Message:在Spring Integration中,Message是任何Java对象连同框架处理对象时使用的元数据的一个通用包装。
它由payload和headers组成。 payload可以是任何类型,headers通常一些必须的数据,如id,timestamp,correlation id, 和返回address。
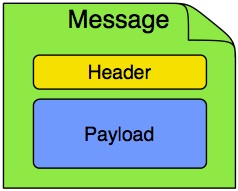
Message Channel:消息生产者发送消息到Channel,消息消费者从Channel接收Message。
Message Channel因此解耦了消息组件,同时也提供了消息拦截和监控的切入点。
一个消息通道可能符合点对点模式或者发布-订阅模式。如果是点对点模式的通道,发布到通道中的每个消息,最多只有一个消费者可以接收。如果是发布-订阅模式的通道,则会尝试广播每个消息给其所有的订阅者。Spring Integration支持这两种模式。

Channel Adapter:Channel Adapter为一个消息端点,连接了发送者或接收者和Message Channel。
一个inbound “Channel Adapter” endpoint连接一个source system到一个Message Channel。

一个outbound “Channel Adapter” endpoint 连接一个MessageChannel 到一个目标系统。

生产者配置
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:int="http://www.springframework.org/schema/integration"
xmlns:int-kafka="http://www.springframework.org/schema/integration/kafka"
xmlns:task="http://www.springframework.org/schema/task"
xsi:schemaLocation="http://www.springframework.org/schema/integration/kafka http://www.springframework.org/schema/integration/kafka/spring-integration-kafka.xsd
http://www.springframework.org/schema/integration http://www.springframework.org/schema/integration/spring-integration.xsd
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/task http://www.springframework.org/schema/task/spring-task.xsd">
<!-- String序列化,下面有使用到 -->
<bean id="stringSerializer" class="org.apache.kafka.common.serialization.StringSerializer" />
<!-- 这里的Encoder在下面没有用到,删掉也可以 Encoder和Serializer只用设置一个就行了。
consumer.xml中的配置也是一样 -->
<bean id="kafkaEncoder"
class="org.springframework.integration.kafka.serializer.avro.AvroReflectDatumBackedKafkaEncoder">
<constructor-arg value="java.lang.String" />
</bean>
<!-- 生产者一些配置属性。不配置按默认执行 -->
<bean id="producerProperties"
class="org.springframework.beans.factory.config.PropertiesFactoryBean">
<property name="properties">
<props>
<prop key="topic.metadata.refresh.interval.ms">3600000</prop>
<prop key="message.send.max.retries">5</prop>
<prop key="serializer.class">kafka.serializer.StringEncoder</prop>
<prop key="request.required.acks">1</prop>
</props>
</property>
</bean>
<!-- 生产者通过这个频道传送消息 基于queue -->
<int:channel id="kafkaTopicTest">
<int:queue />
</int:channel>
<!-- 生产者发送消息设置 -->
<!-- outbound-channel-adapter 发送+频道+分类。该类就是设置这三个的联系 -->
<!-- kafka-producer-context-ref。他是生产者消息的来源地 -->
<int-kafka:outbound-channel-adapter
id="kafkaOutboundChannelAdapterTopicTest" kafka-producer-context-ref="producerContextTopicTest"
auto-startup="true" channel="kafkaTopicTest" order="3">
<int:poller fixed-delay="1000" time-unit="MILLISECONDS"
receive-timeout="1" task-executor="taskExecutor" />
</int-kafka:outbound-channel-adapter>
<!-- 线程池 -->
<task:executor id="taskExecutor" pool-size="5"
keep-alive="120" queue-capacity="500" />
<!-- 消息发送的topic设置。必须设置了topic才能发送相应topic消息 -->
<int-kafka:producer-context id="producerContextTopicTest"
producer-properties="producerProperties">
<int-kafka:producer-configurations>
<!-- 多个topic配置 -->
<!-- 每个topic对应一个类。topic中的broker-list是kafka服务(集群)。
key-serializer和key-encoder分别设置序列化和编码。两者只需要设置一个就行。
value-class-type是消息的类型。
value-serializer和value-encoder和key是一样的解释 -->
<int-kafka:producer-configuration
broker-list="localhost:9092" key-serializer="stringSerializer"
value-class-type="java.lang.String" value-serializer="stringSerializer"
topic="testTopic" />
<int-kafka:producer-configuration
broker-list="localhost:9092" key-serializer="stringSerializer"
value-class-type="java.lang.String" value-serializer="stringSerializer"
topic="myTopic" />
</int-kafka:producer-configurations>
</int-kafka:producer-context>
</beans>
这里可以分成两部分,一部分是属性配置,一部分是Spring integration
Spring integration命名空间使用前缀 int,每个Spring integration适配器(模块)都将提供它自己的命名空间,int-随后的是不同模块的名称。
这里提一句和spring-kafka配置的区别:spring-kafka生产者最基本的配置就是:
1、生产者一些配置属性(spring-integration-kafka里也有)
2、创建kafkatemplate需要使用的producerfactory bean
3、创建kafkatemplate,使用的时候,只需要注入这个bean,即可使用template的send消息方法
线程池
<task:executor id="taskExecutor" pool-size="5" keep-alive="120" queue-capacity="500" />
这里是一个异步线程池的XML配置
pool-size:线程池的大小。支持范围”min-max”和固定值
keep-alive: 线程保活时间(单位秒)
queue-capacity:排队队列长度
至于为什么要用异步线程池……emmmm……你猜?
消费者配置
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:int="http://www.springframework.org/schema/integration"
xmlns:int-kafka="http://www.springframework.org/schema/integration/kafka"
xmlns:task="http://www.springframework.org/schema/task"
xsi:schemaLocation="http://www.springframework.org/schema/integration/kafka
http://www.springframework.org/schema/integration/kafka/spring-integration-kafka.xsd
http://www.springframework.org/schema/integration
http://www.springframework.org/schema/integration/spring-integration.xsd
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/task
http://www.springframework.org/schema/task/spring-task.xsd">
<bean id="kafkaDecoder" class="org.springframework.integration.kafka.serializer.common.StringDecoder" />
<!-- 消费者一些配置属性。不配置按默认执行 -->
<bean id="consumerProperties"
class="org.springframework.beans.factory.config.PropertiesFactoryBean">
<property name="properties">
<props>
<prop key="auto.offset.reset">smallest</prop>
<prop key="socket.receive.buffer.bytes">10485760</prop> <!-- 10M -->
<prop key="fetch.message.max.bytes">5242880</prop>
<prop key="auto.commit.interval.ms">1000</prop>
</props>
</property>
</bean>
<!-- 接收的频道 也可以理解为接收的工具类 -->
<int:channel id="inputFromKafka">
<int:dispatcher task-executor="kafkaMessageExecutor" />
</int:channel>
<!-- zookeeper配置 可以配置多个 -->
<int-kafka:zookeeper-connect id="zookeeperConnect"
zk-connect="localhost:2181" zk-connection-timeout="6000"
zk-session-timeout="6000" zk-sync-time="2000" />
<!-- channel配置 auto-startup="true" 否则接收不发数据 -->
<int-kafka:inbound-channel-adapter
id="kafkaInboundChannelAdapter" kafka-consumer-context-ref="consumerContext"
auto-startup="true" channel="inputFromKafka">
<int:poller fixed-delay="1" time-unit="MILLISECONDS" />
</int-kafka:inbound-channel-adapter>
<!-- 线程池 pool-size -->
<task:executor id="kafkaMessageExecutor" pool-size="8"
keep-alive="120" queue-capacity="500" />
<!-- 消息接收的BEEN -->
<bean id="kafkaConsumerService" class="com.kafka.demo.service.impl.KafkaConsumerService" />
<!-- 指定接收的方法 -->
<int:outbound-channel-adapter channel="inputFromKafka"
ref="kafkaConsumerService" method="processMessage" />
<!-- 消息接收的topic设置。-->
<int-kafka:consumer-context id="consumerContext"
consumer-timeout="1000" zookeeper-connect="zookeeperConnect"
consumer-properties="consumerProperties">
<int-kafka:consumer-configurations>
<int-kafka:consumer-configuration
group-id="default1" value-decoder="kafkaDecoder" key-decoder="kafkaDecoder"
max-messages="5000">
<!-- 两个TOPIC配置 -->
<int-kafka:topic id="myTopic" streams="4" />
<int-kafka:topic id="testTopic" streams="4" />
</int-kafka:consumer-configuration>
</int-kafka:consumer-configurations>
</int-kafka:consumer-context>
</beans>
channel
生产者:
<int:channel id="kafkaTopicTest">
<int:queue />
</int:channel>
消费者:
<int:channel id="inputFromKafka">
<int:dispatcher task-executor="kafkaMessageExecutor" />
</int:channel>
大致就是:生产者的channel使用queue,消费者的channel使用一个自建线程池。
关于这个部分,spring官方是这么解释的:
To create an
ExecutorChannel, add thesub-element along with a task-executorattribute.Its value can reference anyTaskExecutorwithin the context.For example, this enables configuration of a thread-pool for dispatching messages to subscribed handlers.As mentioned above, this does break the “single-threaded” execution context between sender and receiver so that any active transaction context will not be shared by the invocation of the handler (i.e.the handler may throw an Exception, but the send invocation has already returned successfully).
翻译过来大概就是:
创建ExecutorChannel,增加子元素<dispatcher>,同时再里面配置属性task-executor,task-executor的值可以引用自上下文。例如,使得用于发送消息的线程池的配置能用于订阅处理程序。就像上面说的,这会打破发送方和接收方之间的单线程执行关系,任何活着的 transaction context都不会被调用处理程序共享(即。处理程序可能会抛出一个异常,但是send invocation已经返回成功)。
//你看懂了吗,好吧我没看懂( ’ - ’ * )
poller
确切来说,轮询器是一种机制,在有变化时轮询不同端点,并在感知到某些内容发生变化后让adapter对其做出响应,就像一个事件。
生产者:
<int:poller fixed-delay="1000" time-unit="MILLISECONDS"
receive-timeout="1" task-executor="taskExecutor" />
消费者:
<int:poller fixed-delay="1" time-unit="MILLISECONDS" />
这里和上面的channel反过来了,
大致就是:生产者的poller使用一个自建线程池,消费者的poller只配置了固定延迟时间为1毫秒。
翻阅官方文档,没有看到相关资料。此处留疑。⚠️
生产者类
生产者有两个类:KafkaProducerService 和KafkaProducerServiceImpl
public interface KafkaProducerService {
/**
* 发消息
* @param topic 主题
* @param obj 发送内容
*/
void sendInfo(String topic, Object obj);
}
@Service
public class KafkaProducerServiceImpl implements KafkaProducerService {
private static final Logger logger = LoggerFactory.getLogger(KafkaProducerServiceImpl.class);
@Autowired
@Qualifier("kafkaTopicTest")
private MessageChannel messageChannel;
@Override
public void sendInfo(String topic, Object obj) {
logger.info("Service:KafkaProducerService------sendInfo------"+topic);
messageChannel.send(MessageBuilder.withPayload(obj).setHeader(KafkaHeaders.TOPIC,topic).build());
}
}
消费者类
消费者可以只有一个类
public class KafkaConsumerService {
private static final Logger logger = LoggerFactory.getLogger(KafkaConsumerService.class);
public void processMessage(Map<String, Map<Integer, String>> msgs) {
logger.info("Service:KafkaConsumerService--------------");
for (Map.Entry<String, Map<Integer, String>> entry : msgs.entrySet()) {
logger.info("Topic:" + entry.getKey());
LinkedHashMap<Integer, String> messages = (LinkedHashMap<Integer, String>) entry.getValue();
Set<Integer> keys = messages.keySet();
for (Integer i : keys){
logger.info("Partition:" + i);
}
Collection<String> values = messages.values();
for (Iterator<String> iterator = values.iterator(); iterator.hasNext();) {
String message = "["+iterator.next()+"]";
logger.info("message:" + message);
}
}
}
}
消费者类会自动去订阅,一旦消息队列中有消息了会立即去消费,当然,kafka也是支持你定时消费和延迟消费的。
Controller类
@Controller
@RequestMapping("/kafka")
public class KafkaController {
private static final Logger logger = LoggerFactory.getLogger(KafkaController.class);
@Resource
private KafkaProducerService kafkaService;
@RequestMapping("/test")
public String test(){
logger.info("KafkaController--------start-----");
kafkaService.sendInfo("testTopic","kafka sendMessage test!");
return "index";
}
}
这个类当然是根据你自己的项目而定。
一些小问题
1、消费者轮询消息的时候,会不断在控制台打印debug,这时需要设置你的log level为INFO
2、关闭的时候,要先关闭kafka,再关闭zookeeper;不然会导致kafka无法关闭。
参考资料
除了特殊说明,其余图片均来自各大网站。
Spring Integration Overview:https://docs.spring.io/spring-integration/docs/4.0.0.M3/reference/html/overview.html
ZooKeeper深入浅出: https://holynull.gitbooks.io/zookeeper/content/%E5%AE%89%E8%A3%85%E5%92%8C%E8%BF%90%E8%A1%8Czookeeper.html
Kafka 中Zookpeer 的作用-原理与实战: https://www.jianshu.com/p/f6261b8f8314
Apache Kafka:下一代分布式消息系统:http://www.infoq.com/cn/articles/apache-kafka(建议看原文)
apache kafka系列之在zookeeper中存储结构: http://blog.csdn.net/lizhitao/article/details/23744675
Kafka数据可靠性深度解读:http://www.infoq.com/cn/articles/depth-interpretation-of-kafka-data-reliability
spring-integration-kafka 2.0 使用:http://kylozw.github.io/2016/05/21/spring-integration-kafka-2.0/